Thought Anchors in Reasoning vs Non-Reasoning Models: Part 1
Jan 2026
The Thought Anchors framework, formalised that not all components of a model’s CoT are equally important, by measuring the counterfactual importance of individual reasoning sentences. If a sentence is perturbed or resampled and the distribution over final answers changes significantly, this sentence functions as an anchor for downstream computation. The paper also proposes the idea of receiver heads, attention heads that concentrate information from later tokens into a small subset of earlier reasoning sentences.
I wanted to study whether anchor structure is a distinctive property of “thinking” models instead of standard instruction models.
I chose to compare a non-reasoning baseline (Gemma-3-4B-IT) to a reasoning model (Qwen 3 Thinking) on GSM8K-style arithmetic problems.
We keep task, format constraints and decoding procedure fixed and ask:
- Do reasoning models exhibit more pronounced receiver heads?
- Where do these receiver heads appear? Given that these receiver heads pull information from a small number of earlier sentences to make available downstream, one might expect that they’re closer to the final hidden states (i.e. in later layers) which determine the output logits.
What is Kurtosis?
In Thought Anchors, a receiver head is identified by how concentrated its backward-looking sentence attention is. For each layer L and head H, we first aggregate token-level attention into a sentence-to-sentence attention matrix where A q,k is the mean attention mass from tokens in query sentence q to tokens in key sentence k.
We then compute a vertical (receiver) score for each earlier sentence that measures how much sufficiently later sentences attend back to it, excluding a local proximity band to avoid trivial adjacent dependencies.
This yields a vector v of backward attention received per sentence. We summarize how peaked this distribution is using kurtosis, κ, where higher kurtosis indicates that the head’s backward attention is concentrated on a small subset of sentences (heavy-tailed / “spiky” receiver behavior), rather than diffusely spread across many sentences. We compute κ(L,H) per example and then aggregate across the dataset (e.g., median across problems) to obtain a stable receiver-head score per (L,H).
Experiment Results
We ran a receiver-head detection pass using mean kurtosis of vertical attention scores across 100 GSM8K rollouts. Receiver heads were defined as heads whose mean kurtosis exceeded the 99th percentile of all layer x head values within a model. Gemma-3-4B-IT had 3 receiver heads out of 272 heads (1.10%), while Qwen3-4B-Thinking-2507 had 12 receiver heads out of 1152 heads (1.04%). Although Qwen’s raw kurtosis threshold is larger, this value is model-specific because the threshold is percentile-based.
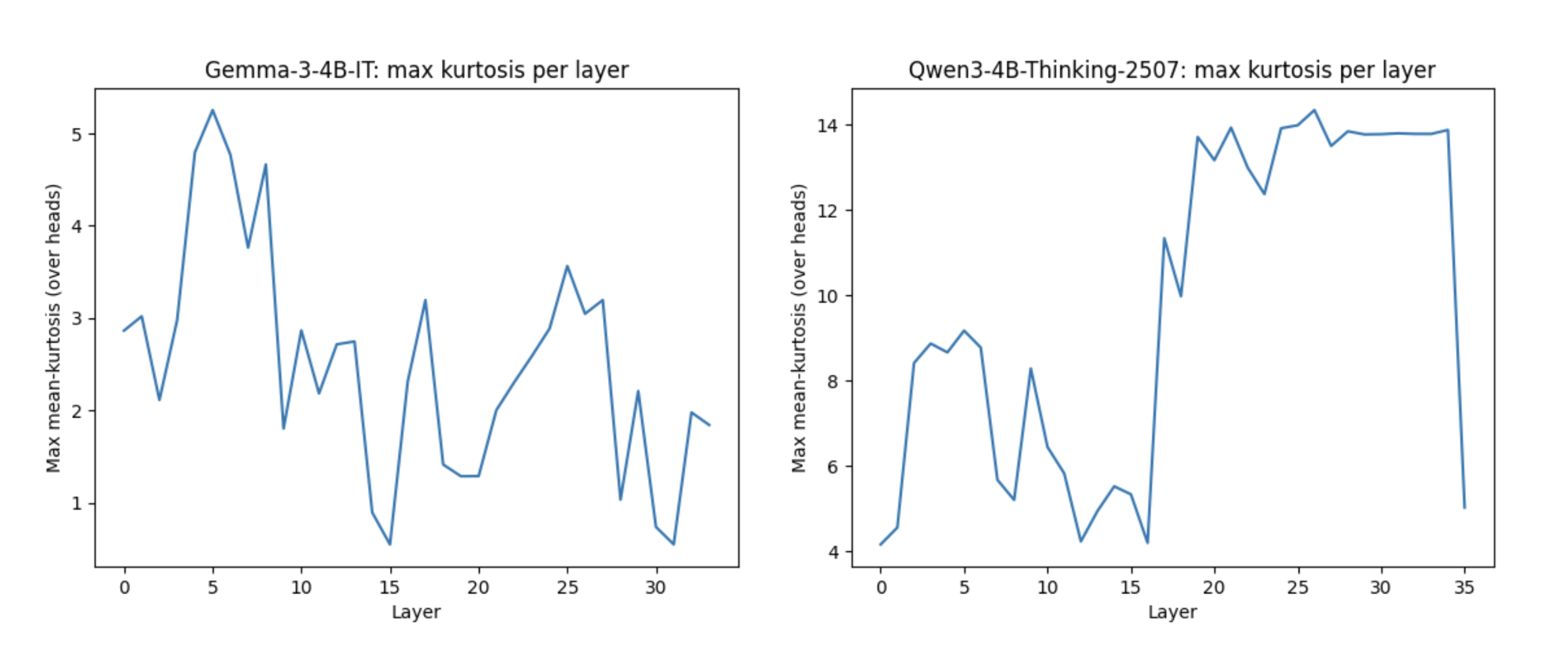
I also wanted to test the hypothesis that “reasoning” models implement stronger sentence-level information routing late in the network. If so, we should see more high kurtosis in later layers, where representations most directly influence the final logits.
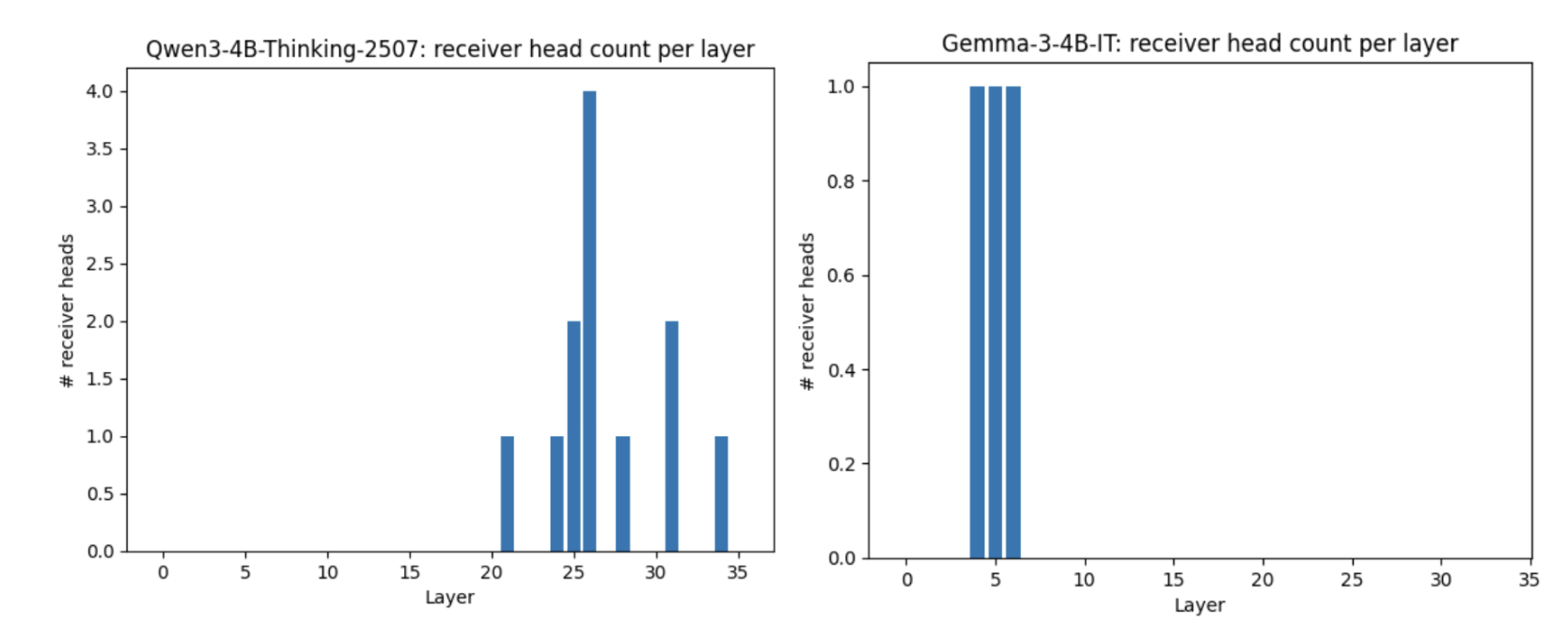
Similarly, we see Qwen3-4B-Thinking exhibits a sharp transition into a high-kurtosis regime in the second half of the network, while Gemma-3-4B-IT peaks early and remains comparatively low afterward. The reasoning model’s receiver-head signal is distributed across multiple late layers, aligning with the idea that sentence-level routing becomes most useful near the output. In contrast, Gemma’s sparse early-layer receiver heads suggest a lesser need for late-stage consolidation.
Conclusion and Limitations
To summarise, both models exhibit a small subset of “receiver heads”, but Qwen-4b-Thinking shows a cleaar late-layer concentration pattern: receiver-head kurtosis rises sharply in the second half of the network and receiver heads are concentrated near the output layers. Using the 99th-percentile cutoff, we do not observe a higher overall receiver-head density in the reasoning model. Instead, the key difference is layer position, as Qwen’s receiver-like behavior emerges late, whereas Gemma’s is sparse and appears primarily in early layers.
There are a few important confounds to keep in mind. First, Gemma-3-4B-IT is instruction-tuned, so any differences we see could reflect instruction tuning vs. reasoning tuning rather than “thinking” per se. A cleaner comparison would have been Gemma base.
Second, receiver kurtosis is sensitive to how we segment the trace into sentences and to the total number of sentences. In this pass, I did not explicitly match CoT length (token or sentence count) across models, so some of the kurtosis differences could be driven by trace-length differences rather than attention routing.
Finally, because receiver heads are defined as the top 1% within each model, this metric is best for asking where receiver heads appear (early vs. late layers), not for claiming that one model has “more” receiver heads in an absolute sense.
See the paper here.
Code Availability here.